聖書「申命記」(約56,800文字)を「テキストマイニング(text mining)※1」により、解析してみました。
テキストマイニングとは、テキストデータの文章を単語や文節、あるいは形態素といわれる品詞など「言語上、意味のある最小単位」で区切ることで、出現頻度、語句の相関関係など、隠れた情報や有用な知見を探し出す(mining:採掘)解析方法のことです。
テキストマイニングツールをすることによって大量のテキストを数値で可視化することが可能になります。
即ち、自然文章(特に定型化されていないテキストデータ)を「自然言語処理技術」によって分割し、その出現頻度や出現傾向を「統計解析技術」・「データマイニング技術」を使って「形態素解析」という処理をすることで、文字情報の傾向や特徴を可視化する技術をいいいます。
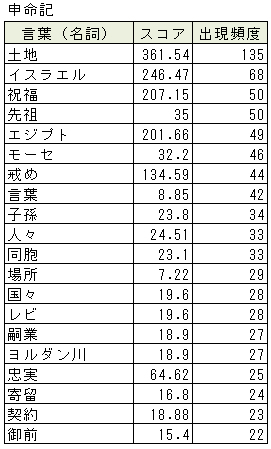
単語(言葉)ごとに表示されている「スコア」は、「重要度」を表し、与えられた文書の中でその単語がどれだけ特徴的であるかを表しています。単語の出現回数が多いほどスコアが高くなりますが、「言う」や「思う」など、どのような種類の文書にも現れやすいような単語についてはスコアが低めになります。
※1:①ユーザーローカル テキストマイニングツールによる分析◆◆◆◆(http://textmining.userlocal.jp/)
◆◆◆②聖書研究ソフト「聖書Navi Active」(H.Taniguchi)による分析 ![]()